O dicionário Merriam-Webster diz (em inglês) que o primeiro uso conhecido da palavra "webmaster" foi em 1993, bem antes de o Google existir. No entanto, esse termo está ficando arcaico e caindo rapidamente em desuso, de acordo com os dados encontrados em livros. Um estudo de experiência do usuário que realizamos revela que poucos profissionais da Web se identificam como webmasters. Eles preferem se intitular otimizadores de mecanismos de pesquisa (SEO), profissionais de marketing on-line, blogueiros, desenvolvedores da Web ou proprietários de site, por exemplo, e raramente escolhem a palavra "webmaster".
Ao discutir nosso novo nome, percebemos que não existe um único termo que resume perfeitamente o trabalho que as pessoas fazem com os sites. Para focar mais nosso assunto (Pesquisa Google), estamos mudando o nome de "Central do webmaster do Google" para "Central da Pesquisa Google", tanto nos sites quanto nas mídias sociais. Nosso objetivo ainda é o mesmo: ajudar as pessoas a aumentar a visibilidade dos próprios sites na Pesquisa Google. A mudança acontecerá na maioria das plataformas nos próximos dias.
Para que as pessoas saibam como melhorar a visibilidade dos próprios sites na Pesquisa Google, também estamos reunindo nossos blogs e documentação de ajuda em um único site.
A partir de agora, a Central de Ajuda do Search Console terá apenas documentos relacionados ao uso do Search Console. Ela continua sendo o lar do nosso Fórum de Ajuda, recentemente renomeado de "Comunidade de Ajuda do Webmasters" para "Comunidade da Central da Pesquisa Google". As informações relacionadas ao funcionamento da Pesquisa Google, ao rastreamento e à indexação, às diretrizes da Pesquisa e a outros tópicos relacionados à Pesquisa estão migrando para nosso novo site, que antes se concentrava apenas na documentação para desenvolvedores da Web. A mudança do conteúdo acontecerá nos próximos dias.
Continuaremos criando conteúdo para todo mundo que quiser que o próprio site apareça na Pesquisa Google, dos iniciantes no SEO aos profissionais da Web experientes.
O blog que você está lendo agora também migrará para o site principal, mas esperaremos uma semana para que os inscritos leiam esta última postagem na plataforma antiga. Mudar tudo isso para o mesmo lugar, incluindo nossos outros 13 blogs localizados, traz as seguintes vantagens:
A partir de agora, todas as postagens arquivadas e novas do blog aparecerão em https://developers.google.com/search/blog. Você não precisa fazer nada para continuar recebendo atualizações. Redirecionaremos os inscritos atuais nos e-mails e no feed RSS para o novo URL do blog.
Nosso mascote, o Googlebot, também ganhou um upgrade. Os passeios solitários dele pela Web chegaram ao fim. Agora, ele rastreará a Internet com uma nova parceira.
Quando conhecemos essa curiosa criatura, nos perguntamos: "Será mesmo uma aranha?" Depois de alguma observação, percebemos que essa aranha robô indexadora pode saltar grandes distâncias e enxerga melhor com luz verde. Acreditamos que a nova melhor amiga do Googlebot seja uma aranha-saltadora, mas parece que ela também tem características de um bot. O Googlebot está experimentando novos apelidos para a pequena aranha robô, mas ainda não escolheu nenhum. Talvez você possa ajudar?
Por hoje, é só. Atualize seus favoritos e, se tiver dúvidas ou comentários, entre em contato no Twitter e na nossa Comunidade de Ajuda da Central da Pesquisa Google.
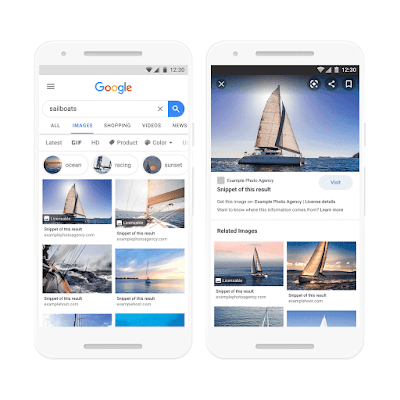
Nos últimos anos, colaboramos com o setor de licenciamento de imagens para aumentar a conscientização sobre os requisitos de licenciamento para conteúdo encontrado no Imagens do Google. Em 2018, passamos a ter compatibilidade com os metadados de direitos de imagem do IPTC. Em fevereiro de 2020, anunciamos um novo framework de metadados por meio do Schema.org e do IPTC para imagens licenciáveis. Desde então, temos visto uma ampla adoção desse novo padrão por sites, plataformas de imagem e agências de todos os tamanhos. Hoje estamos lançando novos recursos no Imagens do Google, que destacarão as informações de licenciamento e facilitarão a compreensão dos usuários sobre como usar as imagens de maneira responsável.
As imagens que tiverem informações de licenciamento serão identificadas com o selo "Licença" na página de resultados. Quando um usuário abrir o visualizador de imagens (a janela que aparece quando a imagem é selecionada), exibiremos um link para os detalhes da licença e/ou a página de termos fornecidos pelo proprietário do conteúdo ou licenciante. Se disponível, também mostraremos um link adicional que direciona os usuários para uma página do proprietário do conteúdo ou do licenciante onde é possível adquirir a imagem.
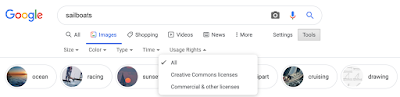
Também estamos facilitando a localização de imagens com metadados de licenciamento. Aprimoramos o menu suspenso de direitos de uso no Imagens do Google para ser compatível com a filtragem de licenças Creative Commons, licenças comerciais ou outras.
Acreditamos que esta é uma etapa para ajudar as pessoas a entender melhor a natureza do conteúdo que procuram no Imagens do Google e como usá-lo com responsabilidade.
Para saber mais sobre esses recursos, como implementá-los e como resolver problemas, acesse a Página de ajuda do desenvolvedor do Google e nossa página de perguntas frequentes.
Para enviar feedback sobre esses recursos, use as ferramentas disponíveis na Página do desenvolvedor para recursos de imagens licenciáveis, o Fórum de webmasters do Google e fique ligado nos próximos horários de atendimento virtual, em que responderemos perguntas frequentes.
"Uma parceria entre o Google e a CEPIC, que começou há quatro anos, garante que os autores e detentores de direitos sejam identificados no Imagens do Google. Agora o elo mais recente da cadeia, que determina quais imagens são licenciáveis, foi implementado graças à nossa colaboração eficiente com o Google. Estamos muito animados com as oportunidades que estão surgindo para agências fotográficas e para todo o setor de imagens devido a essa colaboração. Obrigado, Google." - Alfonso Gutierrez, presidente da CEPIC
"Como resultado de uma colaboração de vários anos entre o IPTC e o Google, quando uma imagem com metadados IPTC de fotos incorporados é reutilizada em um site famoso, o Imagens do Google agora direciona o usuário interessado de volta ao fornecedor da imagem", disse Michael Steidl, chefe do IPTC Photo Metadata Working Group. "Isso é um enorme benefício para fornecedores de imagens e um incentivo para adicionar metadados do IPTC a arquivos de imagem." - Michael Steidl, chefe do IPTC Photo Metadata Working Group
"Os recursos de licenciamento de imagem do Google são um grande avanço para facilitar a identificação e a licença de conteúdo visual. O Google trabalhou em estreita colaboração com a DMLA e os membros dela durante o desenvolvimento dos recursos, compartilhando ferramentas e detalhes, além de receber feedback e responder às dúvidas ou preocupações dos membros. Esperamos continuar com essa colaboração à medida que os recursos são implantados globalmente." - Leslie Hughes, presidente da Digital Media Licensing Association
"Vivemos em um cenário de mídia dinâmico e variável em que as imagens são um componente essencial da narrativa e da comunicação on-line para muitas pessoas. Isso significa que é fundamental que as pessoas entendam a importância de licenciar suas imagens de fontes adequadas para sua própria proteção, garantindo que o investimento necessário para criar essas imagens continue. Esperamos que a abordagem do Google ofereça mais visibilidade ao valor intrínseco das imagens licenciadas e aos direitos necessários para usá-las." - Ken Mainardis, vice-presidente sênior, Conteúdo, Getty Images e iStock by Getty Images
"Com os recursos de licenciamento de imagens do Google, os usuários podem encontrar imagens de alta qualidade no Imagens do Google e navegar com mais facilidade para comprar ou licenciar imagens de acordo com os direitos autorais. Esse é um marco significativo para o setor de fotografia profissional, porque agora é mais fácil para os usuários identificar imagens que podem ser adquiridas com segurança e responsabilidade. A EyeEm foi fundada com base na ideia de que a tecnologia revolucionará a forma como as empresas encontram e compram imagens. Por isso, ficamos muito animados em participar do projeto de imagens licenciáveis do Google desde o início. Hoje estamos muito entusiasmados com o lançamento desses recursos". - Ramzi Rizk, cofundador da EyeEm
"Como a maior rede do mundo de fornecedores profissionais e usuários de imagens digitais, nós da Picturemaxx damos as boas-vindas aos recursos de licenciamento de imagens do Google. Para nossos clientes, como criadores de conteúdo e gerentes de direitos, não apenas a visibilidade em um mecanismo de pesquisa é muito importante, mas também a exibição de informações de direitos autorais e licenciamento. Para aproveitar esse recurso, a Picturemaxx possibilitará que os clientes forneçam imagens para o Imagens do Google em um futuro próximo. Os projetos já estão em andamento." - Marcin Czyzewski, CTO da Picturemaxx
"O Google consultou e colaborou com a Alamy e com outras figuras importantes do setor fotográfico neste projeto. As tags de Licença reduzem a confusão dos consumidores e ajudam a informar o público geral do valor de imagens editoriais criativas e de alta qualidade." - James Hall, diretor de produto, Alamy
"Os novos recursos do Imagens do Google ajudam tanto os criadores quanto os consumidores de imagens, dando visibilidade à maneira como o conteúdo dos criadores pode ser licenciado corretamente. Ficamos felizes em trabalhar em estreita colaboração com o Google nesse recurso, defendendo proteções que resultem em uma remuneração justa para nossa comunidade global de mais de 1 milhão de colaboradores. Ao desenvolver esse recurso, o Google demonstrou claramente o compromisso de oferecer suporte ao ecossistema de criação de conteúdo." - Paul Brennan, vice-presidente de Operações de Conteúdo da Shutterstock
"Os novos recursos de licenciamento do Imagens do Google oferecem opções expandidas para as equipes de criação encontrarem conteúdo exclusivo. Ao estabelecer o Imagens do Google como uma forma confiável de identificar conteúdo licenciado, o Google oferecerá oportunidades de descoberta para todas as agências e fotógrafos independentes, criando um processo eficiente para encontrar e adquirir rapidamente o conteúdo licenciado mais relevante." - Andrew Fingerman, CEO da PhotoShelter
Algumas semanas atrás, fizemos mais uma Palestra Relâmpago da Conferência WM, dessa vez sobre a Pesquisa Aprimorada e o Search Console. O evento teve um chat ao vivo, e muitas pessoas fizeram perguntas. Tentamos responder o máximo possível, mas nossa habilidade de digitação não deu conta do desafio. Por isso, decidimos criar esta postagem do blog para esclarecer outras dúvidas enviadas.
Caso tenha perdido a palestra, assista ao vídeo abaixo. Ele discute como começar a implementar a pesquisa aprimorada e usar o Search Console para otimizar o aspecto na Pesquisa Google.
Os sites que implementam dados estruturados têm classificação mais alta em relação aos concorrentes?
Os dados estruturados por si só não são um fator de classificação genérico. No entanto, eles ajudam o Google a entender o conteúdo da página, o que pode facilitar a exibição dela em resultados relevantes e a qualificação para outras experiências de pesquisa.
Quais dados estruturados são recomendados para páginas de categoria de comércio eletrônico?
Não é necessário usar marcação nos produtos em páginas de categoria. Eles só devem ser marcados quando forem o elemento principal da página.
Quanto conteúdo devo incluir nos dados estruturados? O excesso de dados pode ser prejudicial?
Não existe um limite para a quantidade de dados estruturados que você pode implementar nas páginas. No entanto, siga as diretrizes gerais. Por exemplo, a marcação precisa sempre estar visível para os usuários e representar o conteúdo principal da página.
Em que são baseados os cliques e impressões das Perguntas frequentes?
As páginas de Perguntas frequentes têm uma lista de perguntas e respostas relacionadas a um tópico específico. Ao usar a marcação adequada, as páginas desse tipo podem se qualificar para a pesquisa aprimorada do Google e uma Ação no Google Assistente. Esses recursos ajudam os proprietários de sites a alcançar os usuários certos. Com a pesquisa aprimorada, os usuários podem expandir e ocultar respostas a perguntas específicas, incluindo snippets com respostas. Sempre que esse tipo de resultado aparecer na Pesquisa para um usuário, uma impressão será contada no Search Console. Se o visitante clicar para acessar o site, será contabilizado um clique. Os cliques para expandir e ocultar o resultado da pesquisa não contam no Search Console porque não encaminham o usuário ao site. Para ver os cliques e impressões da pesquisa aprimorada de Perguntas frequentes, acesse a guia "Aspecto da pesquisa" no relatório de desempenho da Pesquisa.
O Google mostra na pesquisa aprimorada avaliações feitas pelo próprio site que as hospeda?
As avaliações não podem ser escritas nem fornecidas pela empresa ou pelo provedor de conteúdo. De acordo com nossas diretrizes de snippets de avaliação: "As classificações precisam ser provenientes diretamente dos usuários". Publicar avaliações escritas pela própria empresa viola as diretrizes e pode levar a uma ação manual.
Alguns tipos de esquema não são usados pelo Google. Por que devemos incluí-los?
O Google é compatível com vários tipos de esquema, mas outros mecanismos podem usar tipos diferentes para exibir a pesquisa aprimorada. Por isso, talvez seja interessante implementar essas opções.
Por que algumas pesquisas aprimoradas que antes eram exibidas deixam de aparecer no Google?
O algoritmo do Google ajusta os resultados da pesquisa para criar o que considera ser a melhor experiência para cada usuário. Isso depende de muitas variáveis, incluindo o histórico de pesquisa, o local e o tipo de dispositivo. Em alguns casos, ele pode determinar que um recurso é mais apropriado que outro ou até mesmo que um link comum em azul é a melhor opção. Consulte o relatório de status da pesquisa aprimorada. Se não há uma queda no número de itens válidos nem um aumento na quantidade de erros, você não tem problemas na implementação.
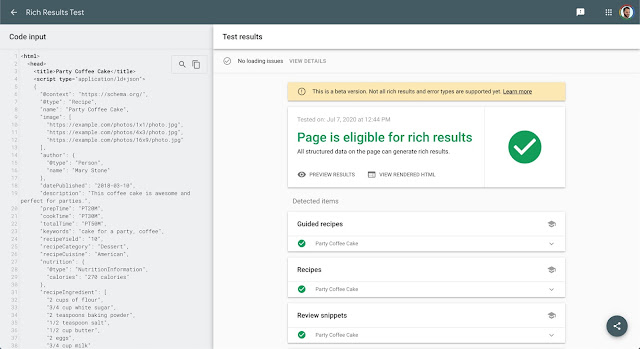
Como posso verificar meus dados estruturados gerados dinamicamente?
A maneira mais segura de verificar sua implementação de dados estruturados é inspecionar o URL no Search Console. Isso dá informações sobre a versão indexada do Google de uma determinada página. Você também pode usar a ferramenta pública de teste de pesquisa aprimorada para fazer a verificação. Se os dados estruturados não aparecem nessas ferramentas, a marcação não é válida.
Como adicionar dados estruturados no WordPress?
Existem vários plug-ins do WordPress (em inglês) que podem ajudar na inclusão de dados estruturados. Verifique também as configurações do tema, que podem oferecer alguns tipos de marcação.
Com a suspensão do uso da Ferramenta de teste de dados estruturados, o teste de pesquisa aprimorada será compatível com dados estruturados que não são usados pela Pesquisa Google?
O teste de pesquisa aprimorada é compatível com todos os dados estruturados que geram esse tipo de resultado no Google. À medida que criarmos novas experiências para outros tipos de dados estruturados, a compatibilidade com eles será incluída no teste. Durante o processo de suspensão de uso da Ferramenta de teste de dados estruturados, analisaremos como oferecer compatibilidade com uma ferramenta genérica fora do Google.
Se não tiver visto as edições anteriores, confira a playlist de Palestras Relâmpagos da Conferência WM. Além disso, inscreva-se no nosso canal do YouTube para ver os próximos vídeos. Assista às estreias no YouTube para participar das sessões de perguntas e respostas e do chat ao vivo de cada episódio.
Postado por Daniel Waisberg, mediador da Pesquisa
Graças aos nossos usuários, recebemos centenas de relatórios de spam todos os dias. Embora muitos dos relatórios levem a ações manuais, eles representam uma pequena fração das nossas ações desse tipo. A maioria delas vem do trabalho que nossas equipes internas fazem regularmente para detectar spam e melhorar os resultados da pesquisa. Estamos atualizando nossos artigos da Central de Ajuda para refletir melhor essa abordagem: usamos os relatórios somente para melhorar nossos algoritmos de detecção de spam.
Os relatórios de spam são importantes para entendermos onde há falhas na cobertura dos nossos sistemas automatizados de detecção. Na maioria das vezes, corrigir um problema subjacente nesses sistemas tem muito mais impacto do que realizar uma ação manual em um único URL ou site.
Em tese, se nosso processo automatizado fosse perfeito, detectaríamos todo o spam e não precisaríamos dos sistemas de relatórios. A verdade é que, embora ele funcione bem, sempre se pode melhorar, e os relatórios de spam são um recurso fundamental para nos ajudar nisso. Em forma agregada, eles permitem analisar tendências e padrões no conteúdo com spam para melhorar nossos algoritmos.
No geral, uma das melhores abordagens para proteger a Pesquisa contra o spam é contar com o conteúdo de alta qualidade criado pela comunidade da Web e com nossa capacidade de exibir esse material por meio da classificação. Saiba mais sobre nossa abordagem para melhorar a Pesquisa e gerar ótimos resultados no site Como funciona a Pesquisa Google. Os proprietários e criadores de conteúdo também podem saber mais sobre como criar material de alta qualidade para fazer sucesso na Pesquisa com os recursos do Google Webmasters. O processo de detecção funciona com nossos sistemas regulares de classificação, e os relatórios de spam nos ajudam a continuar melhorando os dois. Por isso, esses relatórios são muito bem-vindos.
Em caso de dúvidas ou comentários, fale conosco no Twitter.
Postado por Gary